Distributed Machine Learning, Federated Learning, Machine Learning in Wireless Networks
Federated learning is a distributed learning framework that allows machine learning in mobile environments, while protecting user privacy and providing robustness against user dropouts. The global model is maintained at a central server, while the training data is kept on the user device. Rather than sending their local datasets to the server, users locally update the global model. The local updates are aggregated in a privacy-preserving protocol, which is called secure aggregation, at the server, which is then used to update the global model. Secure aggregation ensures that the local update of each user is kept private, both from the server and the other users. The global model is then pushed back to the mobile users for inference.
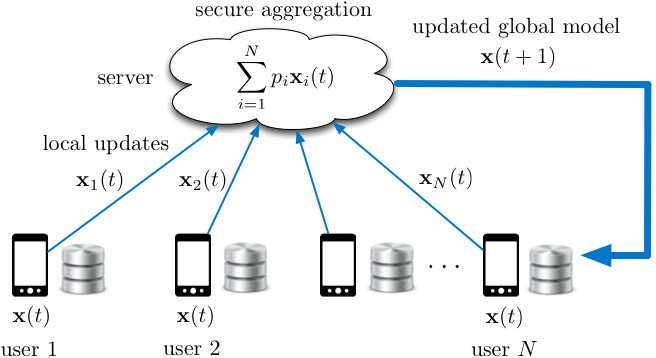
A major bottleneck in scaling federated learning to a large number of users is the overhead of secure model aggregation, which grows quadratically with the number of users. We have proposed a novel secure aggregation framework, named Turbo-Aggregate, that in a network with N users guarantees a secure aggregation overhead of O(NlogN), while tolerating up to a user dropout rate of 50%. Turbo-aggregate employs a multi-group circular strategy for efficient model aggregation, and leverages additive secret sharing and novel coding techniques for injecting aggregation redundancy in order to handle user dropouts while guaranteeing user privacy. Our experiments demonstrate that Turbo-aggregate achieves a total running time that grows almost linear in the number of users, and provides up to 40x speedup over the state-of-the-art protocols in a network with 200 mobile users.
Secure and Privacy-preserving Machine Learning
How to train a machine learning model in a distributed network while keeping the data private and secure? My research builds fast and scalable frameworks to address this problem. These frameworks keep both the data and the model information-theoretically private, while allowing efficient parallelization of training across distributed workers.
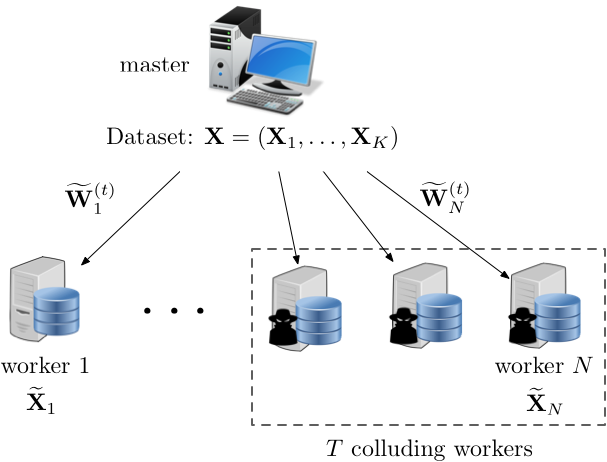
Due to the typically large volume of data and complexity of models, training is a compute and storage intensive task. Furthermore, training is often be done on sensitive data, such as healthcare records, browsing history, or financial transactions, which brings important security and privacy implications. This creates a challenging dilemma. On the one hand, due to its complexity, it is often desirable to outsource the training task to more capable computing platforms, such as the cloud. On the other hand, the training dataset is often sensitive and particular care should be taken to protect its privacy against potential breaches in such platforms. This dilemma gives rise to the following problem, how can we offload the training task to a distributed computing platform, while maintaining the privacy of the dataset?
We introduce a novel framework to enable fast distributed training over a private dataset. Our framework leverages coding and information-theoretic approaches for secret sharing the dataset and model parameters, which reduces the communication overhead and significantly speeds up the training time. As a result, our framework can scale to a significantly larger number of workers, by decreasing the per-worker computation load gradually as more and more workers are added in the system. Experimental evaluations for image classification on the Amazon EC2 cloud demonstrate significant speedup over the baseline protocols, while providing comparable accuracy to conventional logistic regression training.
Scalable and Privacy-Aware Distributed Graph Processing
Graph topologies are important tools for modeling real-world phenomena, such as the topology of the World-Wide-Web, social and biological interactions, or the connectivity patterns in sensor networks. As such, modern applications often require processing large volumes of information that is represented in the form of a graph, such as PageRank, a widely used graph algorithm for ranking webpages in search engines, or semi-supervised learning and graph signal filtering, an important building block of graph neural networks. Distributed computing provides an effective means of scaling-up large-scale graph processes, by distributing the graph storage and computation load across multiple processors (workers) in the cloud.
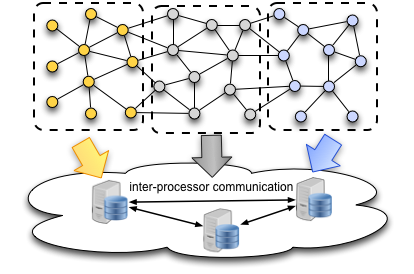
However, this also requires extensive communication and coordination between the processors, which can take up to 50% of the overall execution time, making the inter-processor communication load a major bottleneck in scalability. I design scalable and privacy-aware distributed computing frameworks for large-scale graph and information processing applications, using coding and information theory principles.
Network Information Theory
Another focus of my research is understanding the information-theoretic performance limits of multi-user context-aware communication networks. This is inspired by scenarios in which interacting parties are influenced by side information while interpreting the messages, such as external information resources or knowledge bases representing the unique backgrounds, characteristics, or biases. To do so, my research explores the fundamental limits of the amount of information that can be transferred with a fidelity criterion in a multi-user communication network when interacting parties have access to side information.
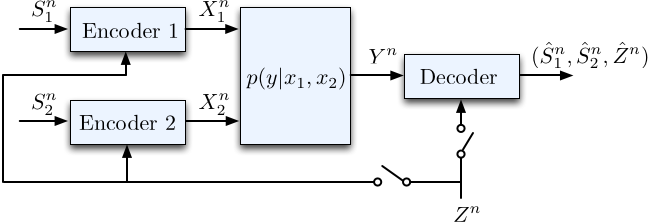
I investigate the impact of shared or differing knowledge bases on the fundamental performance limits when multiple parties transfer information through a noisy channel.
Semantic Communication
Emerging networks such as the Internet of Things (IoT) are designed to facilitate the interaction of humans with intelligent machines. These networks consist of actors with possibly different characteristics, goals, and interests. Such differences can in turn lead to various interpretations of the received information. I design networks that operate under such ambiguous environments, by leveraging the semantic and social features of information transmission. Unlike conventional communication networks, this necessitates taking into account the personal background and characteristics of the interacting parties. For these networks, reliable communication implies that the intended meaning of messages is preserved at reception. In effect, this new generation of networks supports interaction at a level that communicating parties can form social relationships and build trust, which may further affect how the received messages are interpreted. In contrast, communication protocols that operate in the physical layer do not take into account the difference between the meanings of transmitted and recovered messages, but rather are concerned with the engineering problem of reliably communicating sequences of bits to the receiver. These factors together motivate a new approach that molds physical and application layer metrics into one, i.e., a novel performance criterion that takes into account the meanings of the communicated messages. I design mechanisms to achieve this, i.e., how to reliably communicate the meanings of messages through a noisy channel.
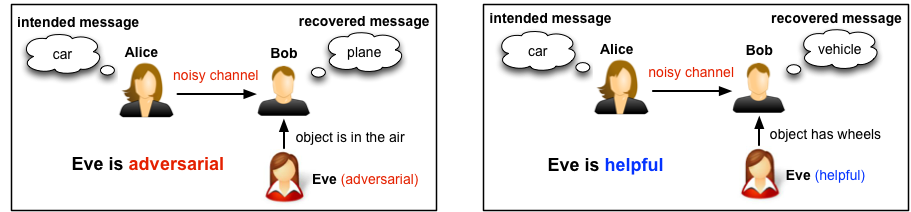
An external influential entity, who can influence how the destination perceives the received information, is considered, to model the impact of social influence on how the messages are interpreted. The exact nature of the individual, whether adversarial or helpful, is unknown to the communicating parties. An individual with such influence capability can have a significant impact on information recovery, hence transmission policies should be tailored to take into account the uncertainty in the intentions of such influential entities.
Heterogeneous Wireless Networks: Interference Management
A heterogeneous wireless network is an environment that consists of cellular base stations of various sizes, coverage areas, and operating protocols. Some of these are installed and maintained by the mobile operator, such as macrocells (cellular towers), while the others are plug-and-play devices installed by the users, such as femtocells.
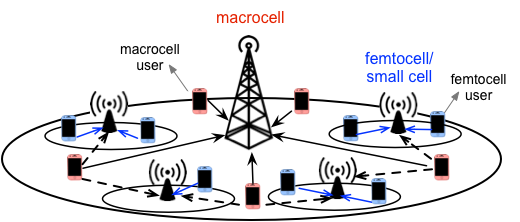
This ad-hoc nature of deployment makes interference management across different tiers a challenge for mobile operators. I addressed this problem in a two-tier network that involves femtocells in addition to macrocells. Mobile user devices as well as base stations are deployed with multiple antennas, which creates spatial dimensions that can be used for interference cancellation or data rate increase. To alleviate cross-tier interference, interference received from the macrocell users can be aligned in a small dimensional subspace at multiple femtocells, while simultaneously ensuring that the performance requirements of the macrocell users are satisfied. This can enable coexistence with high data rates even at very high interference levels, when communication would be impossible otherwise.